In an era dominated by data-driven decision-making, valuable and actionable insights have never been more essential for business success. This need has led to the rise of data marketplaces as a revolutionary solution that connects data providers with data consumers. But what is a data marketplace, and how can you use them to your company’s advantage?
This blog dives into the essentials of Data Marketplaces – what they are, and the compelling reasons why integrating one might be a game-changer for your business.
What is a Data Marketplace?
A data marketplace is a platform that brings together data providers and data consumers, facilitating the buying and selling of data. It serves as a dynamic hub where data creators and consumers converge; where a variety of data products are listed and made available to potential buyers.
Data marketplaces typically host a diverse range of datasets from different sources and providers, spanning various domains and industries. They often offer features like search and filtering capabilities, allowing users to discover relevant datasets based on their specific needs. They may include additional functionalities such as rating and review systems, pricing models, and data preview options. They focus on creating a marketplace environment where users can explore and select datasets from multiple providers, promoting transparency, accessibility, and ease of data discovery.
Getting to Know the Data Marketplace Ecosystem
The data marketplace ecosystem typically consists of the following key stakeholders:
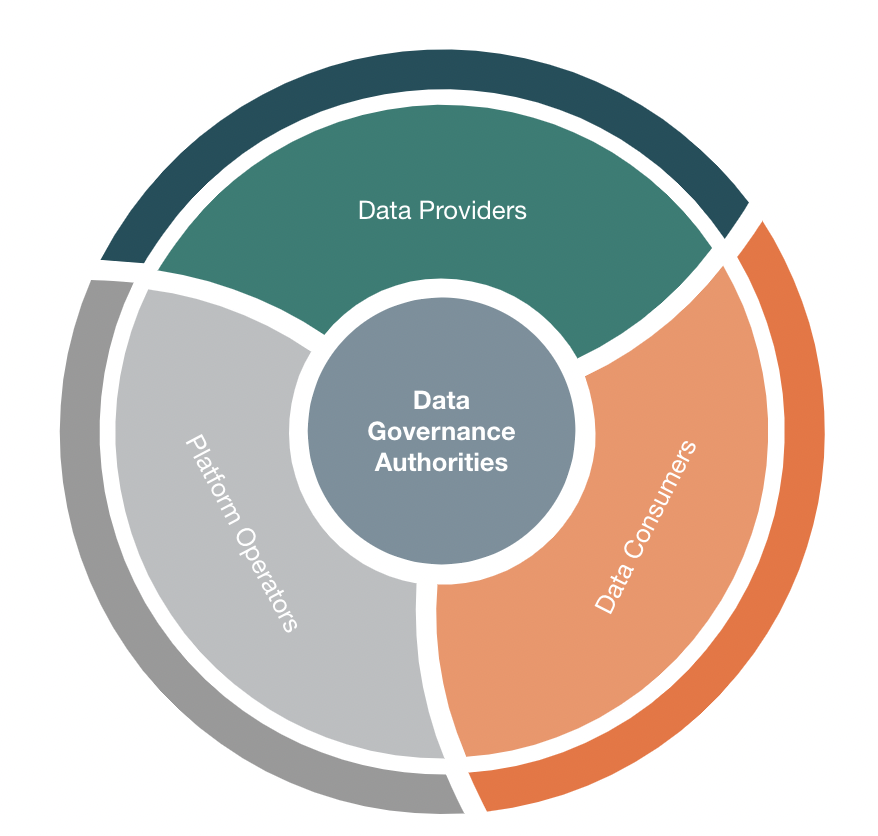
Data Providers
These are organizations or individuals who offer their data assets for consumption. For example, anonymized patient data exposed by healthcare organizations can be used by pharmaceutical companies and consumed by researchers for clinical trials and drug development. They can be data aggregators, data brokers, research institutions, or even individual users who possess valuable data.
Data Consumers
These are organizations or individuals who seek access to specific datasets for analysis, research, or business purposes. For example E-commerce platforms use this data to analyze user behavior and purchase history to offer personalized product recommendations, Pharmaceutical companies and researchers use patients data for their clinical trials and drug development
Platform Operators
These are the entities that develop, maintain, and operate the data marketplace platform. They provide the infrastructure, security measures, and services necessary for data providers and consumers to interact within the marketplace.
Data Governance Authorities
In most cases, data marketplaces may have data governance authorities or regulatory bodies that establish policies, standards, and compliance requirements for data exchange and usage. These entities ensure that data privacy, security, and legal considerations are upheld within the marketplace ecosystem. Data governance authorities help ensure that data within the marketplace is managed, protected, and used in a responsible and compliant manner.
Data Marketplace Benefits
The data marketplace facilitates the seamless exchange of data across various entities whether within an organization, across industries, or even beyond geographical boundaries. Think of it as an organized marketplace for data, where valuable insights and information are readily available. Here are some of its benefits:
Catalyst for AI and Analytics
Data fuels AI and analytics initiatives. A data marketplace provides a rich pool of data for training AI models and conducting advanced analytics.
Unlocking Data’s Potential
Your business generates a plethora of data – structured, unstructured, and everything in between. A data marketplace harnesses this potential by making data accessible to those who can derive value from it. It's a catalyst for turning raw data into actionable insights.
Accelerating Innovation
In a data marketplace, different stakeholders can access diverse datasets. This fuels innovation as creative minds from various domains collaborate, leading to fresh perspectives and inventive solutions.
Efficient Resource Utilization
Rather than each department or team siloing their data, the data marketplace centralizes data resources. This streamlines data collection, avoids duplication, and optimizes storage costs.
Data Monetization
Data Marketplaces allow organizations to develop and execute a data monetization strategy. They can choose to sell raw data, derived insights, or data-driven services, depending on their business objectives. For example, Healthcare organizations can aggregate and anonymize patient data to sell to pharmaceutical companies and researchers for clinical trials and drug development. E-commerce platforms can analyze user behavior and purchase history to offer personalized product recommendations. They can also sell this data to third-party retailers or advertisers looking to target specific customer segments.
Agility in Decision-Making
Timely access to pertinent data fuels quick and well-informed decisions. Relevant data is just a few clicks away, eliminating bottlenecks caused by data retrieval.
Collaboration Beyond Boundaries
If your business operates on a global scale, a data marketplace bridges geographical gaps. Teams from different locations can effortlessly exchange data, fostering collaboration.
Enhanced Data Governance
A well-structured data marketplace enforces data governance policies. It ensures data quality, security, and compliance, thus maintaining integrity across the board.
Expectations and Use Cases
The rise of data marketplaces has created significant expectations and opportunities across various industries. Organizations can leverage data marketplaces to enhance their business intelligence capabilities, for example. They gain access to external datasets that complement their internal data, enabling them to generate comprehensive insights and make data-driven decisions.
Data marketplaces serve as valuable resources for researchers and developers, as well. They can access specialized datasets for scientific research, machine learning model training, and innovation, accelerating their projects and fostering collaboration.
This is why they have gained traction across various industries, empowering organizations to access and leverage valuable datasets for a wide range of applications. Industries such as finance, healthcare, marketing, and transportation can leverage data marketplaces to enhance their services. Users can access real-time data feeds, consumer behavior data, geospatial data, and other relevant datasets to improve customer experiences and drive innovation.
Here are a few practical examples of industries where data marketplaces are extensively used:
- Financial Services: Utilizing external data sources for risk assessment, fraud detection, and customer insights.
- Healthcare: Leveraging medical records, research data, and patient-generated data for personalized medicine and healthcare analytics.
- Retail and E-commerce: Using customer behavior data, market trends, and competitor insights for targeted marketing and business intelligence.
- Smart Cities: Integrating data from various sources to optimize city operations, traffic management, and resource allocation.
Data marketplaces are rapidly evolving and offer tremendous potential for organizations to tap into the power of external data assets. However, careful consideration of data quality, privacy, security, and compliance is essential to ensure the success and trustworthiness of these marketplaces.
Challenges and Security Considerations
While data marketplaces offer immense value, ensuring security and privacy is of paramount importance. These are among the challenges facing organizations:
Data Privacy: Data marketplaces must establish robust privacy measures to protect the sensitive information contained in the datasets. Compliance with data protection regulations, anonymization techniques, and secure data transmission protocols are critical to maintaining privacy.
Data Quality and Trust: Data marketplaces need to implement mechanisms to verify the quality and authenticity of datasets. This includes data validation processes, transparency in data provenance, and reputation systems that establish trust between data providers and consumers.
Secure Infrastructure: The marketplace platform itself must have robust security measures in place. This includes secure authentication and access controls, encryption of data at rest and in transit, regular security audits, and protection against cyber threats.
Examples of Data Marketplaces to Know
Data marketplaces have proven to be effective platforms for data exchange across diverse industries. Depending on the specific requirements and field of expertise, one can discover other platforms customized for your industry or use case. Here are some noteworthy real-world instances of successful data marketplaces:
AWS Data Exchange: Amazon Web Services (AWS) Data Exchange is a data marketplace that allows data providers to securely publish and monetize their data products. Data consumers can easily find, subscribe to, and use the data they need for various applications and analytics.
Microsoft Azure Marketplace: Microsoft Azure Marketplace offers a wide range of data products, including datasets, APIs, and machine learning models. It enables data consumers to discover and access data assets that can be integrated into their Azure-based applications and workflows.
Google Cloud Public Datasets: Google Cloud Public Datasets presents a dynamic data marketplace within the Google Cloud Platform, offering a diverse range of public datasets for analysis. Spanning various industries and disciplines, this platform empowers users to execute big data analytics and machine learning workloads without the complexities of data movement.
Snowflake Data Marketplace: The Snowflake Data Marketplace grants seamless access to live, ready-to-query datasets from various providers across multiple industries. This platform allows users to explore and utilize a diverse array of data without the need for data copying or movement, offering a convenient and efficient solution for data consumers.
Kaggle Datasets: Kaggle, a platform for data science and machine learning competitions, hosts a dataset repository where users can discover and download various datasets contributed by the community.
Quandl: Quandl is a data marketplace that offers a vast collection of financial, economic, and alternative datasets. It caters to financial professionals, data analysts, and researchers looking for historical and real-time data.
Experian Online Marketplace: Experian is a global information services company that offers a wide range of services including credit reporting, data analytics, and decision making solutions
Data.gov: Data.gov is a public data portal provided by the U.S. government, offering access to a wide range of open datasets from various federal agencies.
Datarade.ai: Data marketplace and platform that connects data buyers with data providers. It serves as a marketplace for the exchange of various types of data, catering to businesses and organizations in need of data for analytics, research, and other purposes
The Future of Data Marketplaces
As the data-driven landscape continues to evolve, the future of data marketplaces holds immense potential to reshape industries, foster innovation, and democratize data access. Here is a glimpse into what lies ahead:
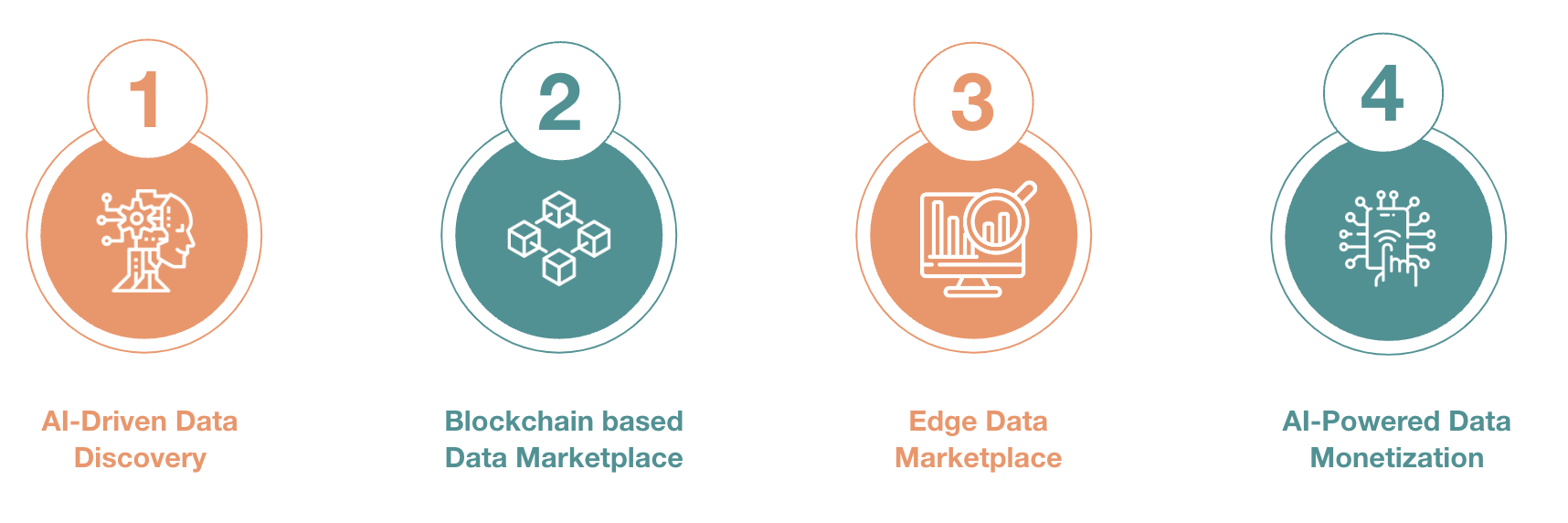
- AI-Driven Data Discovery
- Advanced AI algorithms will enable personalized data discovery, suggesting datasets based on user preferences and context.
- Smart search engines will enhance data accessibility, making it easier for users to find relevant information.
- Blockchain based Data Marketplace
- Blockchain technology can enhance data trust, transparency, and data lineage in Data Marketplaces.
- Edge Data Marketplace
- Data Marketplaces may extend to edge computing environments, offering data closer to where it's generated.
- AI-Powered Data Monetization
- AI algorithms could assist in pricing and monetization strategies for data providers, optimizing revenue generation.
Looking ahead, the future of data marketplaces holds immense potential. Advanced AI algorithms will personalize data discovery, enhancing accessibility. Blockchain technology may enhance data trust and transparency. Data marketplaces may extend to edge computing environments, and AI-powered strategies could optimize data monetization.
These developments are poised to reshape industries, foster innovation, and democratize data access in the evolving data-driven landscape. Embracing the evolving landscape of data marketplaces is key to staying at the forefront of data-driven innovation and success.
Is a Data Marketplace Right for You?
Data marketplaces have emerged as transformative platforms that revolutionize the utilization of data assets, offering a powerful solution for businesses, researchers, and industries alike. These platforms enable the easy access, sharing, and monetization of diverse datasets, driving data-driven innovation, collaboration, and growth in the digital age.
They empower organizations to overcome challenges, unlock new insights, create revenue streams through data monetization, and foster a data-driven culture. Embracing the concept of a data marketplace allows organizations to position themselves for success in the data-driven era, leveraging data to drive growth, competitiveness, and strategic decision-making.
Are you considering incorporating a marketplace in your organization’s data strategy? GlobalLogic helps our client partners build end-to-end solutions that improve customer engagement, optimize operations, and bring innovative new products to market faster. Learn more about our Data & Analytics Services here.
More helpful resources:
- Accelerating Data Platform Adoption & Frictionless Use Across the Enterprise
- The Evolution of Data & Analytics Technologies
- Improving Digital Transformation Outcomes with Hyperautomation


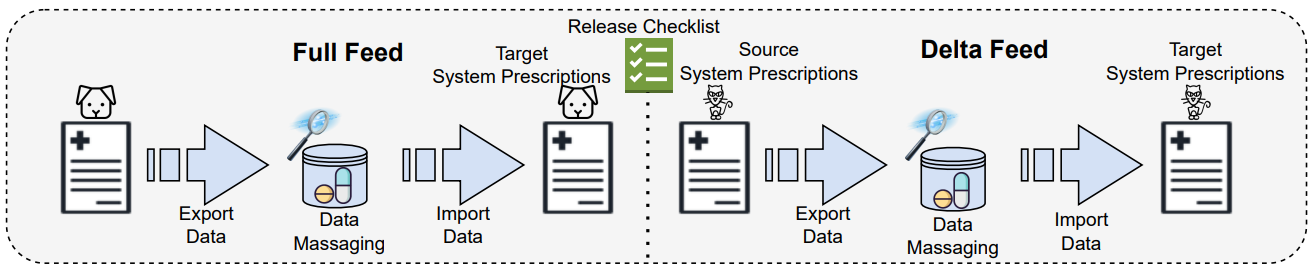
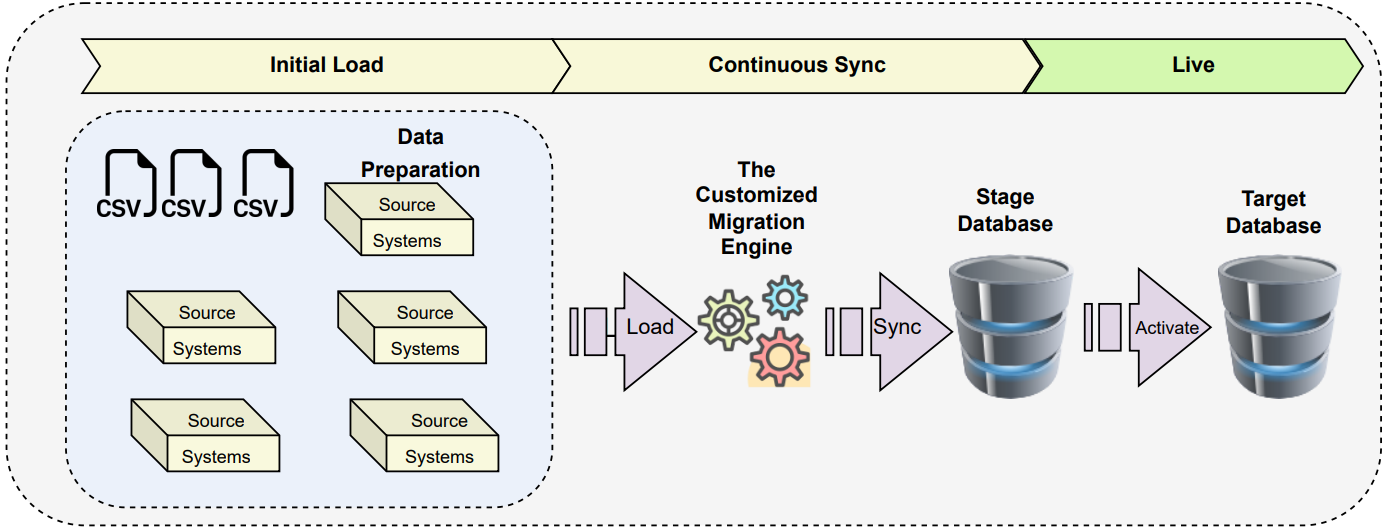
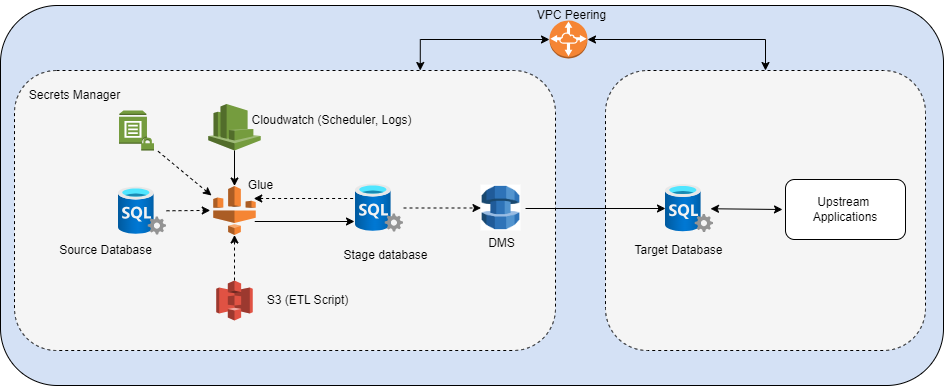
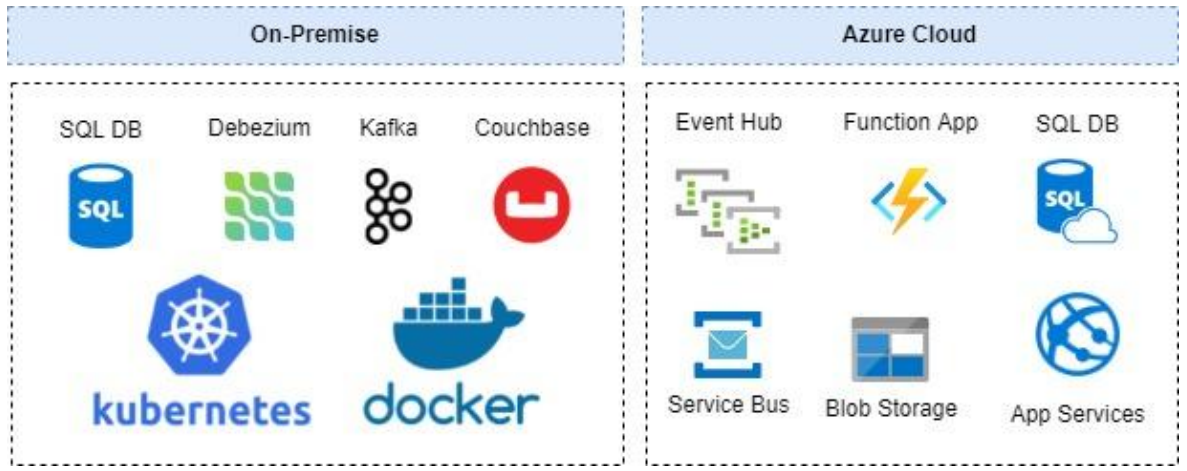
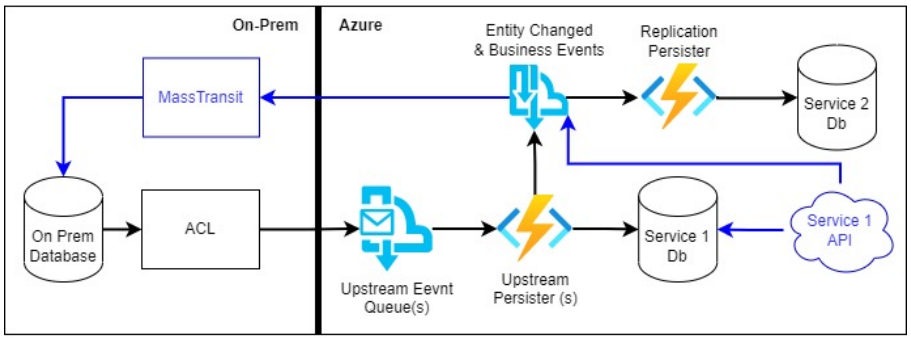
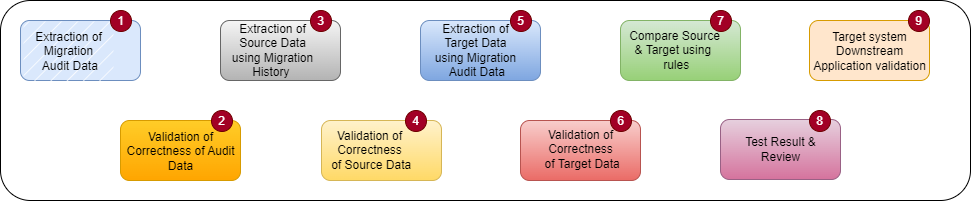

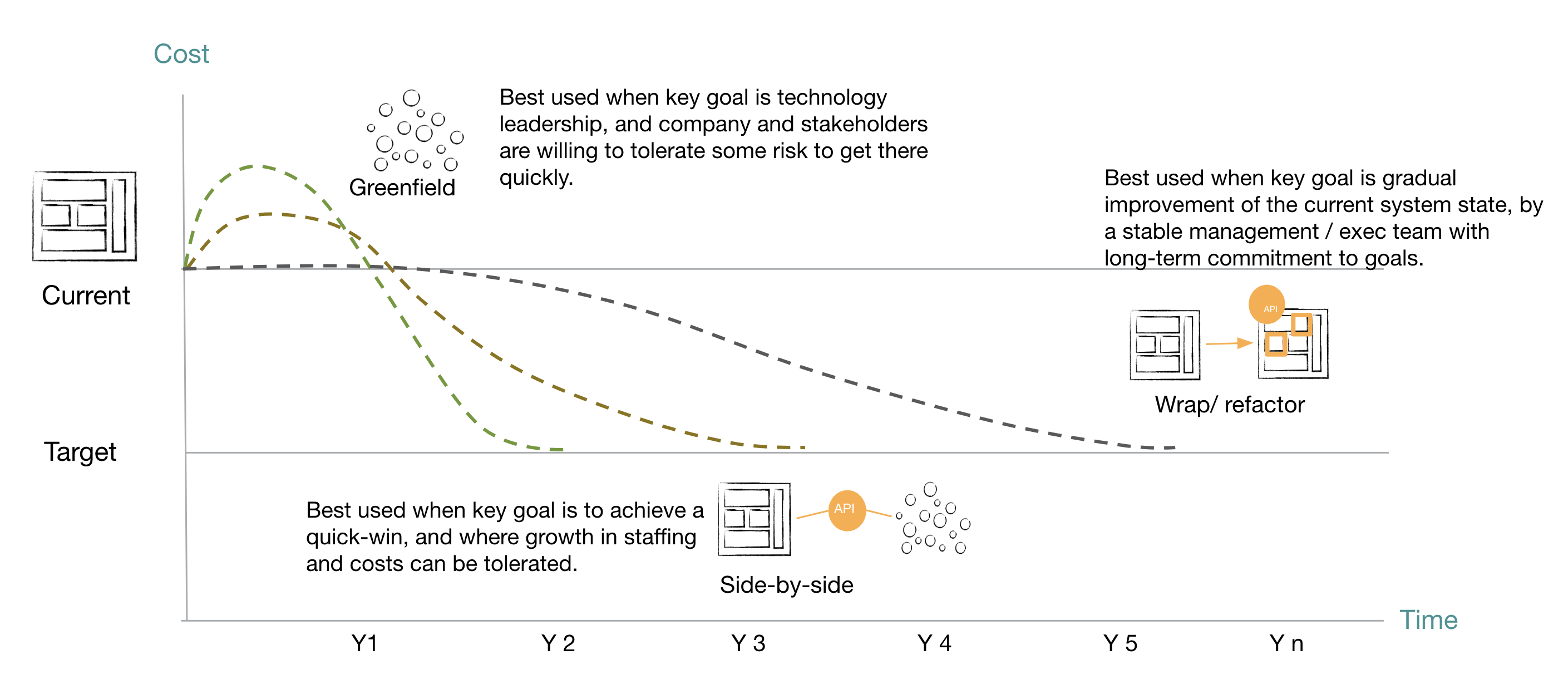 Figure: Modernization Choices - GL POV
Figure: Modernization Choices - GL POV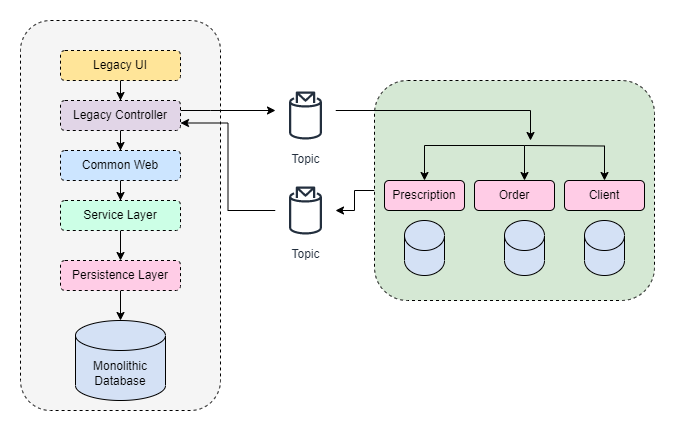 Figure: “Two-way” data sync
Figure: “Two-way” data sync Figure: The Orchestrator Layer
Figure: The Orchestrator Layer Figure: The final go live using custom Migration Engine
Figure: The final go live using custom Migration Engine