Mixed Reality (MR) merges real and virtual worlds to produce new environments and visualizations where physical and digital objects co-exist and interact in real time. For example, Microsoft Hololens augments reality through 3D holograms, enabling device users to interact with these holograms via hand gestures or voice commands.
Tech giants like Facebook, Microsoft, Apple, and Google see significant potential in the XR (Extended Reality) space and have already launched their toolkits and devices in the market. XR technology is becoming mainstream now, and the developer ecosystem is also evolving rapidly. These new ways of interacting with an application create an entirely new immersive experience for the end user and opens up new possibilities in product development.
In this Cafe session from GlobalLogic's Mobile Practices Team, we introduce the landscape of Extended Reality, basic concepts of Mixed Reality, and how to create a professional app for Hololens and Unity.
Join the free digital event experience and learn how to enable open, agile teamwork on a large scale with the power of the cloud. Tune in on November 9th and get unique information and trends.
Teamwork is changing faster than anyone expected. Teams that are able to adapt and work together openly will survive and be successful in the long run.
The Team Tour will cover the latest trends in remote working, ITSM, enterprise agility and how to stay resilient in times of change. You will be the first to see how we develop cloud products for modern teamwork.
Join other industry-leading IT and technology executives, directors and decision-makers. You’ll have access to inspiring sessions, live Q&A and hands-on tips and tricks – right on your screen.
“Regressions” are a serious problem in many software projects. Especially in legacy systems, regressions can indicate a code base that is “fragile” — that is, one where a change in one area can break something in a totally unrelated feature. In more modern systems, regressions are generally indicators of process problems (e.g., an overly complicated source code branching strategy, or not using an “Infrastructure as Code” approach to version control your environments). In either case, regressions are generally perceived as indicators of some underlying problem, and a high rate of regressions is a legitimate cause for concern.
A “regression” is something that used to work that no longer does. In other words, the software has gone backward (regressed) in response to a change, rather than moving forward. The nightmare regression situation is code that has become so fragile that it breaks whenever you make a change. This often happens in legacy systems that were — or have become — tightly-coupled and monolithic. In fact, this fragility can progress to the point where a system becomes literally unmaintainable. Any change, no matter how small, incurs such a high cost of testing and debugging that further changes become economically unviable.
However, there are other causes for apparent regressions besides a fragile code base, and getting the true cause sorted out early can speed resolution of the issue and avoid mis-diagnosis.
Tracking Regressions
In the below made-up “regression tracker” example, cells E8 and E11 appear to be regressions in the classical “code change breaking something else” sense. Judging by the version numbers, there were no major changes made to the environment, the data, or the test case itself that would have caused a test that had previously passed to suddenly fail. The only significant change is the build itself. Our first suspicion, therefore, is that this is a coding problem —something is broken that used to work. While analysis is needed to be certain, we have good reason to suspect this to be a literal regression.
For cells K10 and L13, we should suspect — absent specific knowledge to the contrary — that a change in the test case itself may have caused the failure. Both tests had been consistently passing in previous builds, even in multiple environments and data configurations. The only significant change here—in addition to the build—is that the test case version has changed. We should therefore look at changes to the test case as a potential cause for this apparent regression, in addition to looking at the code itself. Note that the outcome of this analysis can go either way: the new test case might be right, while the old test case that had been passing was wrong. However, we at least know there is a bug somewhere—in the test case and/or in the code—and that this is probably not a classical regression. It is more likely either an issue with the new test, or a long-term bug in the code that was not caught by the old test.
On the subject of long-uncaught bugs, I like the saying, “Don’t confuse the end of an illusion with the beginning of a crisis.” A bug that has been in the code base for a long time does not become a regression when it is finally discovered. Unless it’s something that used to work and no longer does, it’s not a regression. If it never worked (or hasn’t worked for a very long time), it’s your state of knowledge that has changed, not the state of the system. While fixing this bug may be important now that you know about it, treating it as a “regression” mischaracterizes it and can lead to the wrong root-cause action. The right action — besides fixing it plus any related issues — is to improve the test process so that future bugs of this nature will be caught sooner.
Resolving Regressions
As you see in the tracker, we strongly recommend “versioning” everything: the environments, the data, the test cases and the code. Versioning “data” can mean different things in different contexts. In some cases, it might mean versioning the database schema or schemas; in others it might be an identifier for a given test data set. In the case of NoSQL and event-driven architectures, the “data version” might describe a configuration-controlled set of contracts. In any case, we recommend that when versioning anything, follow the convention that a “breaking change” gets a new major version number. For example, a change from data version 3.8.1 to data version 4.0.0 would indicate a breaking change, while a change from version 3.7 to 3.8 would not. Breaking changes need to be planned for and staged; minor changes should be reverse-compatible, and everything should “just work.”
In the case of cell I9, there was a major change made to the data configuration between the previous test run (where the test had passed) and the current test run. This may well be an indicator that the code being tested has not been adapted to accommodate the new data version. If this is the case, cell I9 is not a regression in the sense that one code change broke something else; rather it’s a failure of the code to support a (presumably planned) major data version change. While perhaps a fine distinction, knowing the probable cause of the issue can speed resolution.
The failures indicated by cells J11, J12 and F17 indicate possible environment issues. For cells J11 and J12, the same version of the test case had been passing in multiple previous environment versions. The major breaking change to the UAT environment from version 1.8.0 to 2.0 is a possible source of these failures, which should be evaluated in addition to the code itself. In the case of cell F17, the same version of the test case against the same version of the code failed in the staging environment, but it passed in the UAT environment. We should suspect some environmental dependency there — or else code that is not tolerant of certain environment features, rather than a regression per se.
Conclusion
While simple in concept, tracking a test’s pass-fail history together with the relevant environmental and execution factors is a powerful tool to understand the root cause of failures that are, or that can appear to be, regressions. This tracking requires a number of best practices, such as getting your test cases under source control (and versioning them), as well as versioning execution environments, test data, and sometimes schemas or contracts. The benefit, however, is the ability to identify the root cause of an apparent regression quickly and objectively.
Every organization talks about how their people are their most important asset, but what are organizations really doing to attract, grow and retain the best possible talent?
SHL is a leading Workplace Transformation Company that uses powerful and transparent AI technology, data science, and objectivity to help companies attract, develop, and grow the workforce they need to succeed in the digital era. In this GlobalLogic Cafe session, we’ll be talking with SHL's CTO, Mark Brincat, about the talent equation and the challenges in the market today — and learn how digital technology can give companies a big boost in finding the right people, and developing them into next generation leaders.
Summary: Last Friday, Atlassian announced a consolidation of its license offering, focusing on both cloud and data center platforms. The Server deployment option will be discontinued within the next three years. Read here what this means and how Meelogic, as an authorized Atlassian Solution Partner, can help you migrate to the cloud or data center.
For us as Atlassian Solution Partner, this development comes a little bit earlier than expected, but overall it is the logical consequence of the “cloud-first” approach that Atlassian has been following for several years. Last Friday, October 16, 2020, the time had come. Via blog post Scott Farquhar, one of the two Atlassian founders, announces the end for the server variant. In a little more than three years, more precisely as of February 02, 2024, the end is to be finally reached. Atlassian will no longer sell any new licenses for the platform server from February 02, 2021. Anyone who uses servers today can continue to work with them for another 3 years without restrictions. However, there will be further developments only for the remaining platforms.
What will change for server customers
Atlassian has announced the following changes for its server products on 10/16/202020
End of Sale from 02 February 2021 (No new server products can be purchased after this date. At the same time there will be a price change for Server Upgrade and Renewal licenses.)
End of user tier upgrades and downgrades from February 02, 2022
End of new marketplace app sales from February 02, 2023
End of Support as of February 02, 2024 (support and troubleshooting for all server products will be discontinued as of this date)
Massive investments in “cloud” and “data center
With this decision Atlassian underlines its “cloud-first” strategy. The company is well aware that this decision will not meet with a positive response from all customers. Farquahr believes that some may find the transition difficult. However, the focus on the remaining platforms should lead to even faster and continuous improvement of the products in the long term.
Atlassian has already been investing massively in its Software-as-a-Service offering for several years. Customers can create a new instance within minutes. With up to 10 users and fewer features in the “Free Plan”, this is now even possible without any costs. From an economic point of view in particular, the cloud offers decisive advantages, as there are no costs for hardware, hosting or maintenance.
However, it is in the nature of things that cloud customers, compared to on-premise customers, give up a bit of self-determination to the service provider. New features, for example, cannot simply be turned off or programmed away. Cloud users also have little or no control over the timing of the introduction of some changes. These are the things you have to accept if you don’t want to burden yourself with the issue of hosting.
Also in terms of individualization, the possibilities are limited compared to a system that is operated on your own infrastructure. However, this can also be an advantage. A system in which not every bit and byte can be turned inside out gives those responsible much more time to focus on the essentials, namely the content, its organization and the (automated?) processes around it.
Atlassian Trust Center
However, Atlassian’s investment in its cloud service is not just in technology for more and better features, higher availability and faster performance. Atlassian also had to make some changes in terms of legal certainty, as the important European market in particular was threatening to lose touch with the cloud. At the Atlassian Trust Center at https://www.atlassian.com/de/trust, Atlassian provides its customers with all information on data protection, compliance, reliability and security.
Migration discounts and support
Atlassian offers loyalty discounts to eligible customers to upgrade to cloud products. In addition, the Atlassian Migration Program (AMP) is designed to provide step-by-step instructions, free migration tools, a dedicated migration support team and a free trial of cloud migration for the duration of the remaining server maintenance of up to 12 months.
With all the legal certainty and migration support offerings, and with the help of Solution Partners, there will always be reasons for companies to operate a system “behind the firewall”. For these customers, Atlassian continues to offer the data center version of its products. Atlassian also provides technical and price support for migration to data centers from servers.
AWS cloud is the leading solution for delivery around the world. Do you need some computing power in Ireland? Granted. You want big storage on the west coast? No problem. Anytime, 24/7 you can manage your infrastructure in dozens of datacenters, always picking the most appropriate for your use case. What many don’t know is that several regions are special: the U.S. Government cloud and China. They are so-called “AWS partitions” — aws-us-gov and aws-cn, respectively.
While working with U.S. government agencies is not typical for most companies, the huge Chinese market is a very good way to quickly and permanently boost sales. AWS China proposes the same flexibility as AWS global, but with some caveats. Many GlobalLogic customers have recently requested deploying to AWS/Azure in China. There are not too many articles and resources about Chinese specifics, so the only way was to create a new account and test it by ourselves.
It is clear that AWS in China is not exactly AWS. Technically yes, it is controlled by AWS and has many services and APIs that you can see in AWS global, but due to regulations, their data centers are operated by Chinese companies: Sinnet in Beijing, and NWCD in Ningxia. It is also neither connected to any other regions nor shares any global services.
Key differences to note include:
Separate partition name (in ARNs), separate domain name (so it also affects IAM)
No direct connection to other regions (traffic goes through internet)
Smaller amount of services (with some of them never going to be added, like VPN)
Separate user accounts
Separate S3 (yes, this also means a separate namespace)
No access to Route53 global
To even start working with AWS China, you need to have a license that requires Chinese identification
Service APIs can be a bit different
You need to have an ICP license for hosting any public resource
The list is much longer, but you’ve got the point. Since other articles already cover these key differences — as well as other basics —we will focus now on actual deployment issues. We recently developed a production solution using AWS (details below) and discovered some interesting things during testing.
Everything deployed to Ningxia with Terraform
EKS cluster with Istio and some basic components (cluster-autoscaler, coredns and so on)
Istio as a service mesh
About 25 services deployed with Helm (~100-150 containers)
Various AWS resources like S3, RDS, SNS, SQS and so on
Gitlab pipelines, with Gitlab server living in Ireland and Gitlab runner in China
No direct public access to any resources, the only entrypoint was a separate proprietary gateway
Based on the testing of this product, we found that the biggest impacting aspect is the Great Firewall (GFW) of China. From Wikipedia: “The Great Firewall of China is the combination of legislative actions and technologies enforced by the People's Republic of China to regulate the Internet domestically. Its role in Internet censorship in China is to block access to selected foreign websites and to slow down cross-border internet traffic”. While most people know that the internet is limited in China, the real implication is not clear, though obviously it makes cross-country connections very slow. As in, dial-up modem level slow.
Why is it a big deal? Well, even if you only expect to work with customers, you should still build and deploy your services, migrate some data, provide access to testers and developers, and so on. Every part of the process might/will be affected. Even opening the AWS Console takes time, so don’t expect to somehow “fix” it in future; just expect that all access from the outside world will not be quite good. For a quick test, you can just check how quickly this page opens: https://www.amazonaws.cn/en/. Based on our tests, dependencies download, pushing artifacts, and even pulling the source code takes a ridiculous amount of time.
To make it even worse, it looks like the GFW has intermittent outages. If your application or some software tries to access blocked services (and believe me, almost every big outside site is blocked), your whole connection might be blocked or reduced in throughput. We’ve seen deployments take multiple hours in China, with the same deployments only taking 30-40 seconds in Europe. While it is not clear what usually leads to this problem, it can also be related to GFW resetting connections due to our Gitlab server being some new IP and using SSL.
And speaking about dependencies: everything is blocked. Don’t even try to pull something from quay.io or any other public repository. You can try to find a Chinese mirror, but there are no guarantees; it can contain malware or be simply outdated. They are also very slow. The only way to go is to mirror every dependency to China by hand — possibly waiting for days, as connection speed can go down to 40-50 kbps. And yes, you should mirror every dependency, as you never know when you will get an issue due to something else being blocked.
So in summary, here is a list of the issues we have faced:
Console, deployment, interaction (everything is slow in AWS China if you are not accessing it from China)
Most public repositories are blocked and usually you don’t have any good mirrors
Due to some random usage of keywords, even your own infrastructure can be blocked
Due to connection resetting on HTTPS, it is quite impossible to debug some issues (e.g., your Gitlab runner randomly failing to connect back to Gitlab)
Managing dependencies is going to be very difficult; you will need to keep track of all new includes/requirements and mirror them
If your application needs to access any external resources, it will be slow
Well, that’s it. Although AWS China is a good place for new companies to start working with the Chinese market, it requires patience, effort, time, and money to comply with all China’s regulations and limits. If you’d like some more information about AWS China, you can check out some of these other articles:
Working remotely has, for years, existed only on the periphery of mainstream organizational activity. COVID-19 ensured that remote collaboration is no longer a luxury and has to become an integral part of basic hygiene of an organization. GlobalLogic has been embracing Distributed Agile Principles and practices using processes and tools for a period of time. In this GlobalLogic Cafe session, Mayank Gupta (Agile Practice Lead, GlobalLogic) talks about how to embrace agility in the times of COVID-19.
In this blog series, Oleksandra Skybina (Project Manager & Agile Practice Head) and Andrii Kulshan (Business Analyst & Product Owner) from GlobalLogic’s Kharkiv engineering center discuss the structure and roles of an Agile Scrum team.
In Part I of our blog series, we talked about the different (and sometimes converging) roles of the Product Owner, Business Analyst, and Stakeholders in an Agile environment. Now let's talk about the Development Team, including the Scrum Master and Manager roles.
Development Team
The Development Team is a self-organizing system — a team of three to seven people who are qualified to make decisions independently. No one can tell the development team how many tasks they have to do during the iteration. The Scrum Master and the Product Owner can give their recommendations, but it is the Dev Team who should make the final decision on how much work they commit.
The team must be cross-functional, meaning they should have all the resources needed to perform the required work in the sprint. If you need a third-party specialist, such as a UX Designer or DevOps, the Product Owner should take care of that specialist's involvement in advance. You need to plan everything so as to minimize the number of external dependencies at the start of the sprint.
Another important point: Scrum does not recognize any titles within the team. The opinion of each team member is important, and each person can influence when evaluating stories. We also do not create sub-teams within teams; the entire Scrum team is a single unit.
Scrum Master
The Scrum Master (SM) has five main responsibilities:
1. Serve the Team: This is the SM's primary objective. If there is any obstacle in the way of the team, the SM must eliminate it.
2. Facilitate Events: The SM facilitates most Scrum events: sprint planning, standup, retrospectives, demo meetings, etc.
3. Train the Team: That is, to train team members to interact with each other and with business representatives, to optimize processes, increase their efficiency, as well as to explain what goals the team faces in the current sprint, and what are the expectations from customers.
4. Interact with Stakeholders. The SM must teach stakeholders how to interact with the team in the best way (e.g., which processes are accepted for the project, how to work with the team, etc.)
5. Improve Processes. The SM is constantly improving their knowledge in the field of Agile and facilitation. They use every opportunity to improve current processes.
Now let's move on to the two main configurations in which the Scrum Master can exist: a member of the development team or a dedicated specialist. There are both advantages and disadvantages for each configuration.
Scrum Master as Part of Dev Team
Advantages: The SM is well informed about all aspects of development within the team. They have a sufficient level of design and technical knowledge to understand all the details of the current project. If they see that further development will require additional resources or knowledge, they can warn the team in advance and help plan the process properly. It is in their interest as a developer or QA for the team to commit to the required number of items.
Disadvantages: The SM has very little time to do facilitation and training because if you have several unfinished tasks, you are no longer up to facilitation.
Scrum Master as Dedicated Specialist
Advantages: The SM does not have to choose between two roles (e.g., Developer/QA and the actual Scrum Master), and they will be able to spend more time training the team.
Disadvantages: The SM will have less design and technical knowledge, which will reduce their involvement in the details of current tasks.
Manager Role
In Scrum projects, we move from the traditional view of the Manager as a Project Manager to more of a servant-leader position. Thus, the task of the Manager is to provide all the necessary conditions to create high-quality products and to form a culture around the project. They must help the team and the Scrum Master remove obstacles and improve processes.
The Manager participates in the creation of the team, is responsible for the professional growth of people, and keeps their finger on the pulse of the team. The Manager must understand what is happening in the teams, hold regular meetings with Scrum Masters and the Product Owner, and understand the development issues. On the other hand, they must also interact closely with clients in order to build positive, long-term relationships with them.
Quite often, the Manager plays one of the Scrum roles. The Manager can play the role of the Product Owner, but in our opinion, it is better for the Manager to be the Scrum Master. As the PO, the Manager may be tempted to pressure the team to increase productivity (e.g., add tasks, increase their volume, etc.). The Manager will be perceived exclusively as a person who is the source of tasks in the tracker. As a result, the team may not trust such Manager, and people will stop sharing their problems.
In our opinion, it is better to choose the role of the Scrum Master since it will ensure the Manager has the knowledge of the domain and development process. As a SM, the Manager will better understand the team's area of responsibility, get to know the team and each person's role/status, and also be able to quickly overcome obstacles.
The way we visualize and experience indoor spaces is changing drastically, and it is today’s organizations and establishments that are leading the charge. It wouldn't be a false claim to say that technological innovation is completely revolutionizing our experience of place. When it comes to smart spaces and a new experience of place, the wheels of change are already well and truly in motion, and we are well on our way to creating a more connected world. This white paper discusses the concept of indoor navigation and the benefits of having detailed indoor maps for organizations. It highlights the process and the technologies used to create indoor maps and the various industries that can greatly benefit from indoor mapping.
In this blog series, Oleksandra Skybina (Project Manager & Agile Practice Head) and Andrii Kulshan (Business Analyst & Product Owner) from GlobalLogic’s Kharkiv engineering center discuss the structure and roles of an Agile Scrum team.
In a galaxy far, far away, a group of unlikely heroes were building the most advanced product of their time: the Death Star. Ok, so Darth Vader’s imperial engineers aren’t exactly the heroes of the Star Wars saga, but they do illustrate a great example of how a Scrum development team operates — along with the stormtroopers and the officers who respond quickly to the changing demands of the Emperor (aka, Stakeholder) that are provided to them by Darth Vader (aka, the Product Owner) and his assistant, who we are calling Mini Vader (aka, the Business Analyst). In Part I of our blog, we'll analyze the roles of the Product Owner, Business Analyst, and Stakeholders.
Product Owner
The Product Owner (PO) is a person who acts as a client representative and presents the results of the Dev team's work. Anyone can serve as a Product Owner: business owners, testers, business analysts, etc. As shown in the above figure, the Product Owner’s area of responsibility is the final product. Their tasks include:
Managing the Backlog: The PO decides what will go into the backlog (i.e., a list of tasks) and what will not, the priorities of the tasks in the backlog, and the value that the solution will bring to the business.
Defining the Minimum Viable Product (MVP): The PO identifies which part of the product can be delivered to clients and end users in the shortest time with a minimum set of features.
Participating in Development: The PO answers the team's questions and participates in all Scrum events, including both daily rallies and so-called “backlog refinements,” where the PO describes tasks and business cases to the team, provides information for quality assessment, and collects feedback on system limitations.
Demo'ing the Product: The PO demos the product for the stakeholders at the end of each sprint and describes in detail the products functionality and compliance with business requirements. They are also responsible for training end users and writing documentation.
Saying "No" to Stakeholders: This is the most important aspect of the PO's job, as they are the ones who collect claims from various stakeholders. Often, tasks and ideas are more than a team can accomplish in a realistic time frame. It is important not just to postpone, but also to completely reject some ideas. The PO must take into account business needs, user preferences, metrics, priorities of different groups, workload and specialization of teams, market trends ,and much more. We can say that this is almost the central task of the PO; based on their experience and knowledge, the PO must select the ideas that will lead the project to success. Some PO's make decisions intuitively, but even in this case, they must be able to explain their "no" to all stakeholders.
Business Analyst
The Business Analyst (BA) transforms ideas into requirements. The role of Business Analyst is sometimes confused with that of Product Owner. The main difference is that BA is a profession, whereas PO is a role in Scrum. While the PO is responsible for the strategic direction of a product, the BA is responsible for the tactics used in developing the product. At the junction of these areas, the two roles intersect. It is not always clear who should write business cases, collect initial requirements, and communicate them to a team — especially in terms of outsourced products, when the roles are not what they seem.
In Scrum projects, the BA helps the PO specify the requirements. The BA can be either part of a team or a stand-alone unit; work with multiple teams; and describe the requirements for different modules or subprojects.
Of course, the role of the BA is not limited to the requirements management only. They can also communicate in the same way with stakeholders and users, analyze the market, and come up with hypotheses (although in an outsourced environment, this is not always possible). As shown in the figure below, we have identified several configurations of the BA and PO interactions, along with the division of their responsibilities.
Based on these configurations, you can better understand your own situation and how to build more effective interactions with the client. Let's consider each configuration in more detail.
BA-PO-Client (Product Group)
The first configuration is perfect. We have the Business Analyst and the Product Owner, and we have the Client (Product Group). If the PO is also a part of this Product Group (i.e., can make decisions and influence the scope of tasks), then everything is fine. The BA specifies the requirements, the PO deals with strategic planning and says “no” to everyone. The client is happy and satisfied with both the system and the fact that the team is self-organized. With this configuration, you can offer the client a full, autonomous development cycle, from idea to implementation.
BA/PPO (Proxy Product Owner)-Client
This is a good configuration for starting a project where you do not yet have the client's trust. Here, the client provides clearly defined business requirements for all stages of the project (i.e., roadmap) and a list of requirements (i.e., backlog) for each team. The BA, who also acts as the Proxy Product Owner, simply distributes these requirements and monitors their evaluation and implementation by the team. Over time and with good relations, this model of work can grow into the first option (i.e., BA-PO-Client), with more freedom for decision-making.
BA-PPO-Client
This is probably the least effective configuration because the chain of decision-making and requirements verification is stretched. Roughly speaking, the PPO is responsible for almost nothing, and the BA does not know what to do — whether it is possible to contact the client directly, or why he needs the PPO. Therefore, try to avoid this model.
BA-Client
In such a model of interaction, the ready-made requirements come from the Product Group of the client, and from your side the BA only helps to work out local functionality, constantly confirming each change. This model occurs when the client has almost no trust in the team.
PO-Client
There is the client, there is the Product Group, there is the Scrum team — and each team has the Product Owner. The PO receives the initiative from the Product Group, processes business cases and requirements, and communicates them to the team. With great decision-making freedom for both the PO and the team, there is no BA in this scheme, so the PO and the team must work together on the tasks that the BA usually performs. Not all teams are happy with the prospects of writing user use cases, so the introduction of such a scheme may be met with some resistance. A transition period from BA - PO - Client is often required, but a successful transformation increases both the efficiency of the whole team, and the quality of development. It also reduces the response time to any changes in business tasks.
To sum up, although the Product Owner and the Business Analyst are conceptually different, but in many tasks they intersect. To understand who you need on a project, you need to find out the client's expectations, their level of trust in you, the needs of the team, and the degree of team autonomy.
Stakeholders
The term "stakeholders" is often found in a professional environment. You might think it's a single person or a few people who always have the final say. This is often the case, but at the same time, this term includes almost all participants in the development, including:
Clients: These are the decision makers, delivery managers, and product managers at the client company. There may also be people in marketing or sales who can help us understand what needs to be done, find out what users expect, and provide market analytics.
Internal/External Users: Depending on what product you are creating, there may be not only end users, but a large group of professionals with ideas for improving the product.
Team: This is the development team that sees and improves the product every day. Many people make the big mistake of not listening to a team, but its opinion can be very valuable.
Miscellaneous: One example of a "miscellaneous" stakeholder is an external regulator. If you are in the medical or financial field, then your products must comply with regulations, rules, and laws that are often controlled by special organizations. You can also add internal regulators to this group, such as the legal department. They do not directly affect the functionality, but they may impose some limitations.
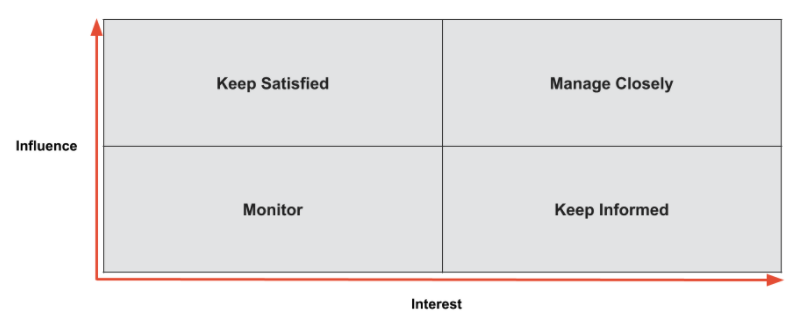
How can you understand how to work with each of these audiences? You can start with a Stakeholder Influence / Interest" matrix, like the one pictured below. It will help to determine where to take a particular group of stakeholders, and how to organize the process of interaction with them.
Manage Closely: This quadrant includes stakeholders who have a great influence and are the most interested in the product. You need to work with this group of stakeholders first.
Keep Satisfied: This quadrant includes stakeholders who are not particularly interested in the product, but have a great influence. These can be the same external regulators or heads of legal departments. You need to make sure that they are satisfied by adding the necessary functionality to the product.
Keep Informed: This quadrant includes stakeholders who are very interested in the product. They usually have a lot of ideas, but they have little impact on the project. They should not feel offended, so we have to inform them.
Monitor: This quadrant includes stakeholders who are not interested and have no influence on the project. However, it is necessary to look at them sometimes because they may suddenly pass into any of the other groups, or they express useful ideas.
In Part II of this blog series, we'll take a look at the various roles and responsibilities of the Development team, including Scrum Master and Manager roles.