As human beings, we want to understand what the future holds for us. We make decisions based on the information available to ensure all risks are either resolved or mitigated. Often, these decisions are based on analysis done on historical data.
Consider this: I plan to run a marathon two months from now. I have never run a marathon – just a couple of 10Ks. I need a plan to prepare myself.
What is the data available to me right now to make this plan? It comes from the preparations I did for my 10K. I did not start running 10K on my first day; I started with 2K. After 10 Days, I was able to take it up a notch to 4K, and a week after that to 5K. It took me a month and a half to practice for my first 10K.
Weather also played a part in my runs. On a humid morning, I could not do a 5K so easily. Cool nights were better. But to make a long story short, I had enough data from my past experiences to begin preparations for the marathon.
Now that I have the data, can I predict my success or failure for the marathon? I still have to create key milestones and KPIs by which to measure my performance. If the marathon is in two months, I should be able to hit 10K in the first three weeks.
Am I in shape to start running 5K to start with? What about the weather? How about where I plan to train? Also, do I have enough time in my schedule to plan for my training?
Similar questions arise in the lifecycle of the products we are building. Leadership – both at the team and program level – need data and information to help remove impediments and bring predictability. These can be driven by two different kinds of indicators: leading and lagging.
Leading Indicators
Leading indicators focus on the inputs going into building a product. These help determine whether we have the right ingredients in place to build the right product in a timely manner.
Leading indicators are hard to measure and a lot of times depend on historical data available at a point in time. In the story above, the leading indicators for me to run a marathon successfully are: How much time will I be putting in everyday to train for the run?
For example, if I say two hours, I can track that on a daily basis and see if I am doing that because if not, I will surely miss my target. In product development, the health of a backlog is a good indicator of where my teams are heading before the start of a sprint or PI. Some other leading indicators can be:
Release Burndown used to track our progress for a release. This will help programs make the right decisions.
Backlog Readiness, as the health of our backlog is a key leading indicator of how our Sprints and PI will go.
Epic Readiness.
Story Readiness.
Capacity v/s Load. Do we have enough work to feed our teams and/or trains?
Stable Velocity. Based on historical data, will our teams be able to achieve the commitments they are making?
Lagging Indicators
Lagging indicators focus on the outcome. They are easy to measure and help develop a pattern of how teams and programs are doing. Leaders can gain insight from this data, do root cause analysis, and find where the bottlenecks might be or what areas to improve.
In my story above, after two weeks of training, reviewing my performance data gave me insight into how well prepared my body was for the run. Based on that insight, I made changes to my routines to ensure I would improve on them in the next two weeks. Lagging indicators can be:
UAT/Production Defects Density, the quality of the code deployed in Production/Higher controlled environments.
The number of unplanned Production Releases. How often are we deploying code in production? RCA will lead to key areas to fix.
Sprint/PI Spillovers (Committed v/s Completed), or the team’s ability to meet the commitments.
Sprint Churn. How stable are our backlogs during the Sprints?
These examples of leading and lagging indicators vary from program to program and based on the point in time or milestone for which you are developing these reports. They can also be different for various leadership groups and the structural hierarchy from which you are looking at product development.
Ultimately, you want your program to define leading and lagging indicators for tracking its health. And last but not least, the data used for building these metrics should come from a single source of truth.
Have you defined your leading and lagging Indicators yet?
Data warehouses are business intelligence systems used to enable reporting as well as data analysis. As such, they can help any data-driven business understand and improve upon their business model.
At its core, a data warehouse is a storehouse for incoming data from multiple sources that integrates data, compiles reports, delivers analytics, and offers a comprehensive view of how to improve business. They are not a new concept, having been around and widely used for many years.
However, the Data Warehouse technology landscape is undergoing a rapid evolution which is primarily being driven by users looking for newer solutions to meet the challenges of the “Data Age,” while also addressing the drawbacks of legacy data warehouses.
The Challenges with Legacy Data Warehouses
Many organizations have been using data warehouses to drive their businesses and enterprises. But over time, the efficiencies of these systems have decreased due to the following factors:
The maintenance and overheads of the existing data warehouse systems have increased.
Data volumes have increased causing performance bottlenecks.
Data has become more varied and complex, therefore, integrating new data sources into the warehouses has become more difficult.
Legacy data warehouses also involve high licensing costs based on the servers and nodes used which have increased due to the explosion in data.
Legacy data warehouses utilized data cubes as the primary data modeling strategy. Data cubes inherently involve creating dimensions and facts for data modeling. With the explosion of data volumes, the constraints of data cubes have resulted in more complex ETL pipelines.
In accordance with Moore's law, computing and storage have become cheaper because of new processing capabilities, even as modern data warehouses have become more optimized due to the increased performance and leveraging of processing power. This allows enterprises to incorporate additional options which can be adopted to process, store and transform data with columnar architectures and massively parallel processing.
With this in mind, users want solutions that address these key points and remove performance bottlenecks, enable scalability, provide flexibility, and enhanced control on billing charges.
Modern Data Warehousing
With the increasing use of cloud technologies, data warehouses have been incorporated into the cloud, offering a compelling alternative choice. This is particularly useful as they can also be integrated into data lakes, creating more flexibility to support large volumes of data and onboard newer data formats.
Modern data warehouses are particularly well suited for:
Scalable workloads
Newer sources of data
Structured and semi-structured data
Analytical reports and dashboards
Evolved data models
Data modeling
Optimized performance
Low overheads
With modern data warehouses, enterprises can process and analyze large volumes of data across a variety of data formats without performance hiccups due to scalable services and massively parallel processing on the cloud.
Another advantage is the increased flexibility to add newer sources and data formats. This has simplified management activities to save time and effort, reduce overheads, eliminate fixed costs and maintenance activities.
Modern data warehouses on the cloud allow enterprises to leverage the latest computing innovations while optimizing performance. As the warehouses run on the cloud, they can also be scaled up to meet any increase in workload while simultaneously being scaled down once the workload is completed. With computation engines based on modern design patterns and technologies, performance of the data processing workloads gets optimized.
Additionally, modern data warehouses see themselves as enablers due to being multifunctional and having the ability to integrate other data stores as well as serve as data lakes and data warehouses with logical data zones within their system.
All of this is available either on per usage or fixed pricing basis which gives users more flexible options.
Technology Options
Below are the tools and technologies available for cloud data warehouses:
AWS Redshift
Snowflake
Azure Synapse
GCP Big Query
AWS Athena with AWS S3
Delta Lake
Anyone looking to modernize their existing legacy data warehouses should evaluate the above options to find the best fit for their needs.
Deciding the Fit
When enterprises are considering a new technology, there are many factors to consider including the requirements, performance, cost, and architectural aspects.
Aside from these, there are also various complexities, maintainability, and extensibility that need to be considered in order to determine the most appropriate technology for the business.
Explore Modern Data Warehouses
At GlobalLogic, we have helped many enterprises upgrade their legacy data warehouses to modern cloud data warehouses to improve performance, reduce maintenance and overheads, and optimize costs. We look forward to helping our partners evaluate the fitment of modern cloud data warehouses by matching their needs with their vision. Please feel free to reach out to our Big Data & Analytics practice at GlobalLogic to discuss and we would be glad to help with any such initiatives.
Michael T. Nygard states, “Too many production systems are like Schrodinger’s cat—locked inside a box, with no way to observe its actual state.”
Testing in production (TiP) lets a software development (Dev) and IT operations (Ops) team prepare for possible bugs. It’s also helpful in analyzing the user’s experience. However, it is essential to understand that testing in production is not releasing untested code in the hope that it works or waiting for the bugs to be detected once end-users use it.
Techniques for testing in production:
A/B testing
Canary deployments
Continuous monitoring
This article covers various facets of TiP and why this is a crucial tool in the paradigm of Shift-Right testing.
Great Expectations for Testing
It’s not easy capturing all defects in the development lifecycle or simulating a live, real-world environment. So Dev and quality assurance (QA) teams put valuable effort into white-box and black-box testing, exploratory testing, and automation testing.
In addition, they are considering more environments like Dev, QA, and User Acceptance Testing (UAT) for validating the user flows. Dev and QA teams test these environments using mock test data to find the defects with all possible scenarios, corner cases, and out-of-the-box strategies, but they cannot capture the end user’s intentions all the time.
Additionally, partially testing code can be dangerous as it does not prove that the code will function correctly in production. Further, it’s important not to wait for issues to arise for users.
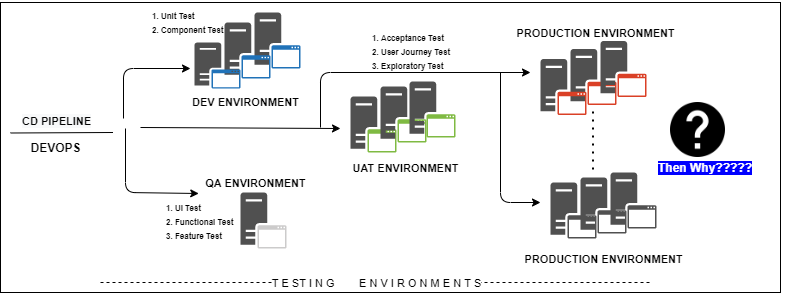
A few case studies and surveys show that top companies constantly release new features to a fraction of their traffic to measure the impact. The figure below shows that most modern software development follows a lifecycle where developed code and testing propagate through increasing environment layers. Finally, the code deploys to production, and we say the product is “go-live” or released.
But how is this reflected in reality? Consider the following myths:
It works in all pre-production environments, and all testing types pass. So it will work in production.
I don’t always test my code, but when I do, I do it in production.
In today’s digital transformation age, with other software deployed, “production” will always have its own set of unique issues. Therefore, it is imperative to have TiP.
TiP – A few key characteristics
So what exactly is TiP, and how do we distinguish this from other tests that happen throughout the lifecycle. A few key characteristics of TiP are:
A set of tests that incorporate new changes with live traffic and a group of users.
Tests that analyze user experience including failures, sudden breakage, slow performance, usability, and acceptance.
Tests that impact the quality of the product by getting continuous feedback from the end-users.
An activity that iteratively and progressively increases customer trust and expectation with a product.
TiP – The various techniques
TiP, also known as Shift-right testing, continuously tests the product when it is in production or near-production. This approach helps software developers find unexpected scenarios that they did not detect previously and ensures the correct behavior and performance of the application.
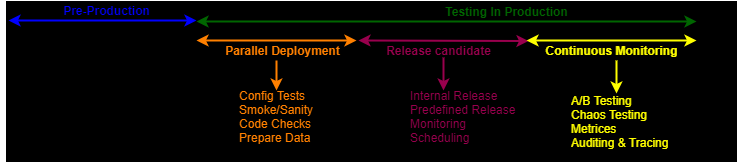
The map below is a representative set of various shift-right techniques that span the TiP lifecycle. These techniques can effectively speed up the overall software release cycle:
1. Bug Bash:
Despite the testing procedures, a few defects are likely to make it past the development phases and into production. There will always be hidden issues, no matter how thorough your testing is or how successful your automated tests are in development, and these bugs can impact end-users.
Bug Bash is one of the methods used by several companies to ensure product quality. Typically, all the internal stakeholders, content team, survey team, marketing team, product owners, etc., are part of the Bug Bash.
Before the product deploys to “live” clients, the latest updated code is put through its phases one more time to ensure everything is in working order. Then, for the Bug Bash, they install the most recent version of the product, play around with the features, and provide feedback.
The core philosophy of a Bug Bash is to get other eyes, typically not those fully embedded into the software teams, on the product before releasing it to production users and ensure we haven’t overlooked anything.
There are eight steps for a successful Bug Bash:
Set a date and time.
Send invites.
Create teams.
Preparing scenarios.
Bug cycle process and template.
Hunting time.
Prizes for an outstanding catch.
Wrap up the bash.
2. A/B Testing
A/B testing, also known as split testing or bucket testing, compares two versions of a website or app to see which performs better. A/B testing is essentially an experiment in which consumers review two or more website variations at random and statistical analysis shows which variation works better for a specific conversion objective.
3. Canary Testing
Canary testing is a powerful technique to test new features and functionality in production while causing the least amount of disruption to users. The words canary testing and canary deployment are interchangeable in this context.
A canary release is a software testing strategy for reducing the risk of releasing a new software version into production by progressively distributing the update to a small subset of users before releasing it to the whole platform. Blue-green releases, feature flag releases, and dark launch releases are commonly used terms for canary releases.
Destructive testing is a software assessment method used to detect areas of failure in a program in an IT context. Essentially, the process entails wrongly interacting with software, such as entering data that is inaccurate or in the wrong format, in order to see if the application would fail if an end-user made that mistake.
Destructive testing (DT) involves a type of object analysis that includes breaking down a material to determine its physical attributes, such as strength, flexibility, and hardness, using a test.
5. Fault Injection Testing
Fault injection testing is a type of software testing that intentionally introduces defects into a system to ensure that it can withstand and recover from them. Fault injection testing is commonly performed before deployment to identify potential flaws introduced during production, generally under stress conditions.
Fault injection testing in software is completed either at compile-time or during runtime. A compile-time injection is a testing technique that involves changing the source code to simulate software system flaws. Modifications or mutations to existing code, such as changing a line of code to reflect a different value, can be used to accomplish these changes. Additionally, testers can modify code by adding or inserting new code, such as additional logic values.
Chaos engineering is when fault injection is a core aspect of a production system. Chaos engineering is a field of study where someone can do fault injection in a chaos experiment. If fault injection is a method of introducing failure, Chaos Engineering is a strategy for implementing fault injection to achieve the goal of more dependable systems.
Chaos testing has grown in popularity to ensure high-quality software while it is still in production. Many firms have benefited from this relatively new method, which has transformed how we assess software’s robustness. Chaos testing is cloud-based resilience testing. However, because today’s networks are so dispersed, they require a high level of fault tolerance. To evaluate this, you’ll need to take a different approach to testing.
Chaos testing, coined by Netflix, is a method of purposefully causing harm to an application in production. The Netflix engineering team developed Chaos Monkey, one of the first chaos testing tools. Chaos Monkey creates faults by disabling nodes in the production network, the live network that serves movies and shows to Netflix users.
User acceptability testing (UAT) is a software development tool where the product is tested in the "real world" by the target audience. UAT is usually the final stage of the software testing process, conducted before distributing the tested program to its target market. The goal of UAT is to ensure that the software is fit for its purpose.
UAT is an excellent way to ensure quality for time and money spent on the program while boosting transparency with software users. UAT also enables developers to deal with real-world scenarios and data, and if successful, confirms that it meets the business requirements.
Best Practices for Testing in Production
Smaller, more frequent releases are the norm in today’s agile world. Although such techniques reduce some dangers, the high frequency raises the chances of releasing vulnerable code in the world. Meanwhile, if done correctly, testing in production can improve the effectiveness of the app testing strategy.
We have curated a list of best practices for TiP:
You must always use real browsers and devices, which may seem obvious, but it is essential to note. The production environment must consist of an actual device, browser, and operating system combination. It’s impossible to judge the software’s performance without putting it in a real-world setting because no emulator or simulator can accurately simulate real-world user conditions.
Timing is everything. When there is a lot of traffic, do timed tests. A genuinely successful application should perform flawlessly even when it is under a heavy load. Since production testing aims to find flaws in the actual world, it must occur under the most challenging conditions.
Bring in a chaos monkey. Netflix engineer Cory Bennett states, “We have found that the best defense against major unexpected failures is to fail often. By frequently causing failures, we force our services to be built in a way that is more resilient.” A chaos monkey randomly throws failure into production, forcing engineers to develop recovery systems and more robust adaptable bug resolution practices.
Monitor continuously. This is necessary to see what is going on with the servers or databases. For successful production testing, monitoring is an absolute must. Keep an eye on critical user performance metrics when running a production test to see whether the test has an undesirable impact on the user experience.
Prioritize the defects reported by end-users. If they require immediate attention, strive to fix them as soon as possible; if they take time, have suitable replies with proof to inform the end-user. Accepting our flaws isn’t a bad thing.
Allow users to engage in exploratory production testing if at all possible. By properly telling people about new features and releases, you may solicit their input. It is feasible to collect end-user insight in this manner without having to worry about disturbing user feedback. In addition, users will be less surprised or upset by bugs if they know that they are beta-testing a product.
We have also put together a table of tools and libraries that will aid your efforts in Testing in Production.
Scenario
Tool/Methods
Benefits
Bug Bash
Slack, Zoom, Skype communication channels.
Rooms to discuss product features and defects.
Catch more bugs - Identifying several types of bugs.
Cut regression testing time.
Incorporate other people’s experiences & perspectives.
Collaborate across teams.
A / B Testing
Google Analytics & Google Optimize
Optimizely
Visual Website Optimizer [VWO]
Reduces bounce rates.
Helps to increase conversion rates.
Results are easy to understand.
Inexpensive.
Increased sales.
Canary testing
-
Only a small percentage of users will be affected by the bug; reduction in risk.
Increased assurance in releasing new features at a faster rate.
Remove the feature as soon as possible if it is defective, slows down the application, or causes negative user feedback.
Shortening the feedback loop and responding to feedback faster by bringing new features to production sooner.
Destructive
Alpha / Beta Testing
Regression Testing
Equivalence Partitioning
Acceptance Testing
Helps to check the robustness of a software product.
Helps to understand predictable software behavior under improper usage.
Fault injection testing and Chaos Engineering
Chaos Monkey
Gremlin
Chaos Toolkit
Improve the resilience of a system.
Stop significant losses in revenue by preventing lengthy outages.
Helps improve incident response.
Improved service availability and durability.
User acceptance testing (UAT)
Fitness Tool
Watir
Usersnap
Provides a finished result that is satisfactory.
Assists in the delivery of a bug-free final product.
Provides users a finished product that is in good operating order.
Fulfills all functionalities that a finished product should have.
Benefits of Shift-Right
Reduces the risk associated with continuous delivery.
Assures customers that the product is ready for production.
Permits engineers to add, erase or change highlights based on feedback.
Increases the efficiency of software.
Supports the distribution of products more quickly.
Captures problems before the end-users see them.
Conclusion
Production testing is increasingly becoming an unavoidable aspect of the testing process. Without genuine user experience, it is hard to forecast and cure all defects when millions of people access a single piece of software from thousands of different devices, browsers, browser versions, and operating systems.
As a result, DevOps-aligned developers and organizations benefit greatly from production testing. It helps to improve user experiences, brand reputation and increases income by allowing developers to be more prepared for dealing with abnormalities.
Production testing is, without a doubt, an essential part of software development in today's world.
Since over 90% of software companies adopt agile methodologies, the number of production releases has increased. Unfortunately, each production release can change how things work in the real world. Therefore, DevOps teams must check all modifications in production as early as possible to ensure the reliability of any program. It can be detrimental to a software company's reputation if they do not discover these issues before the customers.
In our increasingly digitized world, immersive technology like Near Field Communication (NFC) has become the forefront of technological advancement. Exchanging digital content has never been easier, faster, or safer. Connecting real-time data through a simple touch, NFC has already been integrated into everyday technologies like iOS and Android systems, digital smart locks, and contactless cards.
In this paper, explore how NFC technology is changing the world with its extensive, global network and digital solutions. Don’t want to be left behind? Learn more about the NFC digital transformation that has taken hold around the world for consumers and businesses alike.
It would be an understatement to say that the telecom industry is changing. In the past, traditional telecom networks utilized proprietary hardware and software, and numerous operations were manual. Telcos also used to offer conventional consumer-oriented services, and the network was at the center of business.
With the advent of digital technologies and the digitization of networks, IT now plays a central role. Through software-defined networking (SDN) and network function virtualization (NFV), there is hardware and software decoupling and network operations are becoming automated. There are use cases beyond mobile and industry-oriented enterprise use cases enabled by 5G and the Internet of Things (IoT).
Additionally, customers are becoming the center of telco business. As a result, telcos face a survival imperative to be “tech-driven” and transform into “digital” telcos to compete with over-the-top (OTT) systems and internet players.
To deal with this unprecedented period of technology innovation, telcos need a north star for their business that provides a shared vision for their products, services, technology, and customers. They must focus on the following business imperatives to develop and define their north star strategy:
Expand consumer engagement.
Transform and grow the networks.
Expand business engagement.
Expand Consumer Engagement
Telcos need to make the customers the center of their business and manage and deliver high-quality experiences. Therefore, telcos must implement the following business use cases to develop a north star approach to expand consumer engagement:
UC1 – Omnichannel Customer Engagement across all digital touchpoints.
UC2 – Advanced personalization such as recommendations, cross-selling, and upselling.
UC3 – Simplify business offerings by combining telco and non-telco products into unified offerings.
UC4 – Business agility through time to market in hours or days instead of months.
UC5 – Partner lifecycle management by partner on-boarding, provisioning, monetizing, and settlements.
UC6 – Exposure of IT, Network, and Partner capabilities to the ecosystem for open collaboration.
UC7 – Seamless and immersive consumer services enabled by 5G for Augmented Reality (AR), Virtual Reality (VR), Gaming, and 4K Video.
Transform and Grow the Networks
Networks form the “core” of the telecom business. Telcos need to manage and deliver an ultra-fast network experience to the consumer to meet the challenges of super-exponential growth in bandwidth demand. Additionally, telcos need to implement the following north star business use cases to transform and grow the networks:
UC8 – Monetize the investment in 5G.
1 – Transformation to Cloud native network architecture.
2 – Intent Based Networking.
3 – Network Intelligence and Automation powered by Artificial Intelligence (AI) and Machine Learning (ML) technology.
4 – Edge Computing.
Expand Business Engagement
Telcos must implement the following north star components to business use cases to create greater value for Enterprises, Server Message Blocks (SMB), aggregating their network capabilities, and specialized vertical industry solutions:
UC9 – Advanced Enterprise and SMB services such as Fixed Wireless Access, Enhanced Software-defined Wide Area Network (SD-WAN), and Value Added Services such as teleconferencing services leveraging AR/VR enabled by 5G.
UC10 – Smart Home, Smart Cities for Waste Management, Emergency Services, Logistics Management, Vehicle to Everything (V2X), and Industry 4.0 enabled by 5G.
Summary
Telcos have a tremendous opportunity ahead of them with the capabilities of 5G, SDN, NFV, IoT, AI, and ML technologies. It may be challenging to decide which products or technologies to focus on and where exactly to begin. Defining and establishing the north star business imperatives and use cases mentioned above will help create alignment and momentum across the entire telco organization.
GlobalLogic Telecom's service portfolio uses the critical business imperatives outlined above as its foundation. We are excited to work with our telco clients to accelerate their digital transformation journeys, and we would be happy to discuss your own needs after filling out the below contact form.
Financial challenges can be difficult to overcome with the constraints of daily life, but financial security is achievable with the right planning and tools. Understanding your financial challenges and the opportunities available is key to unlocking financial security.
There are numerous variables to consider when creating a financial plan. However, you can achieve financial wellness with proper insight, setting achievable goals, and technological tools. Read about the essential factors to consider and available resources to attain financial wellness.
Making the case for more efficient pre-authorization
The concept of authorization in the U.S. healthcare market is not a new one. However, the process itself has not yet matured and there is plenty of opportunity for improvements in automation and technology.
Authorization is a process whereby a provider submits a request to ensure that any given medical treatment is covered by the insurance company. This enables insurance companies to manage costs and provide their patients with higher quality care. It also helps to regulate the value-based care initiatives rendered by providers.
There are two main types of authorization.
Prior or Pre-Authorization: The healthcare provider obtains approval for the patient’s services prior to their being rendered. This happens in the majority of authorization-seeking cases. Learn more about prior authorization in this resource from America’s Health Insurance Plans (AHIP).
Retro Authorization: In rare exception cases and emergencies where pre-authorization is not possible, retro authorization may be requested from the insurance company after the patient’s treatment has been provided.
Payers are increasingly moving towards the automated and more regulated pre-authorization model, enabling them to optimize healthcare costs by approving requests within a quick turnaround time when all criteria are met. However, newly introduced protocols are putting more burden on the providers. In some cases, patients worry that pre-authorization creates delays rather than moving the process forward.
The healthcare industry was at the forefront of the pandemic and as such, had the greatest need for quick, digitized solutions with lower overhead to manage volume at the height of the crisis.
Some insurers were forced to temporarily suspend some pre-authorization requirements as the pandemic made it even more difficult to process paperwork in a timely way. These are among the reasons the healthcare industry has felt the pressing need for quick, adaptable pre-authorization solutions.
Pain Points with the Current Pre-authorization Process
There are several issues with the current pre-authorization process that make it more cumbersome and time-consuming than is ideal.
Approximately 66% of prescriptions rejected at the pharmacy require prior authorization, resulting in nearly 30% of these prescriptions being abandoned by patients. The reality that it takes 5-10 days for the insurance company to approve an authorization request can also delay procedures that can result in longer times to diagnosis, as well.
Further, the prior authorization physician survey conducted by the American Medical Association in December 2020 found that 69% of practicing physicians reported their health insurers had either reverted to pre-pandemic pre-authorization policies or never relaxed these policies in the first place. Only 1% of responding physicians said their health insurers maintained relaxed requirements through the end of 2020 when the U.S. health system was buckling under the strain of record numbers of COVID-19 cases.
There are several other issues with pre-authorization process problems that prevent it from being a smooth process.
It’s a Cumbersome Process for Providers
Much time is wasted in providing information to the payers with too many manual interventions in the process.
There is no clear picture for providers on which medical procedures need immediate attention for pre-authorization and which do not.
Patient Care May Be Delayed
The real impact of delayed care is felt by patients who don’t get their medication or treatment on time.
With delayed processing of pre-authorization requests and responses, claim requests may be denied due to incorrect information.
Lack of Standardization in Payer Rules for Various Insurance Plans
Even though many rules have been rolled out by Centre for Medicare and Medicaid Services (CMS), many insurance companies still follow different processes with varying rules on how to intake the pre-authorization request from the provider and process it further into the system.
There are no set rules and standards yet that are being followed across every payer.
Manual Interventions
Pre-authorization via faxes and paper forms needs a lot of manual intervention before the request can be processed accurately within the system.
New CMS Guidelines for Pre-authorization
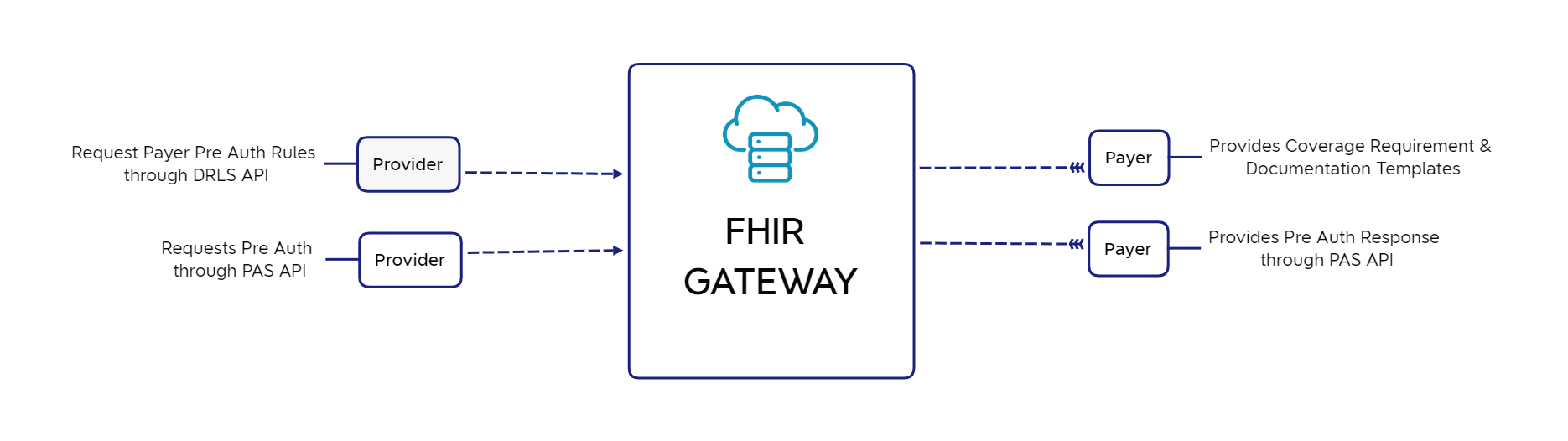
In Dec 2020, CMS proposed new (final) rules to help streamline the pre-authorization process. These are designed to bring consistency and transparency to the API and services so end-users can make the right decisions and achieve better outcomes.
Organizations building solutions in keeping with these new rules can incorporate these features:
Medicaid, CHIP, and QHP payers will be required to build APIs that can enable and streamline data processing. Medicare Advantage Plans are currently excluded from this rule.
Providers will be able to electronically inquire about Pre-Auth requirements for a specific payer and items/services.
Providers will be able to electronically submit Pre-Auth Requests and receive acknowledgment (in coordination with existing HIPAA X12 transactions).
System integrations should support electronic status updates for the case/claim, as per the API standards.
There should be an ability to provide supplementary context information to support the Pre-Authorization.
Both providers and patients should have access to more information on claims status.
Pre-authorization Improvement Initiatives
The Fast PATH Program Initiative for Pre-Authorization
A new program initiative called the Fast Prior Authorization Technology Highway (Fast PATH) was launched by America’s Health Insurance Plans (AHIP), along with several of the organization’s member insurance providers, to improve the pre-authorization process.
Prescribed Medication Pre-Auth Process
With the help of Surescripts technology, the most important clinical information will be made available to the doctors while the patient is still dealing with and getting informed about the prescribing process. A simpler, smoother process at the pharmacy counter will help the patient receive and take the medication quicker and easier.
Medical and Surgical Procedures Pre-Auth Process
Using Availity technology, physicians can access a multi-payer portal to simplify pre-authorization requests and approvals that may be required for different procedures. The multi-payer portal allows for easier communication, faster approvals, and quick turnaround, which in turn helps to speed up the delivery of quality patient care.
Automation & Digitalization of Pre-Auth Process
Automating digitizing the pre-authorization process can provide benefits including coordinated care, fewer claim denials, minimized healthcare costs, and quick decision-making from payers. This will ultimately support the transition to value-based care.
With each upcoming year into healthcare, more importance and highlights have been given to improve the quality of care given to patients and more regulations to incentivize the physicians so that they focus more on giving value-based care to members.
When physicians focus more on value-based, quality care, insurance payers can reduce the restrictions imposed on pre-authorizations. This can also help reduce the utilization of resources and time required to respond to requests.
A few of the steps that have been taken or are about to be taken for the digitization of the Pre-Auth process are described below:
Solution Category
Solution Element
Benefits
Real-time and automated pre-auth
Real-time UI for providers to submit request / Get response to pre-auth (using TPA solutions like Availity and Emdeon).
Quick approval and response time with real-time transactions happening between providers and payers.
Using EDI 278 transaction requests to send in real-time and in batches.
Standardized and HIPAA-compliant transactions would help in streamlining prior authorization approvals.
Auto-population of the Patient, Provider, Procedure, and medical treatment details in the filling system.
A more customer-centered approach for pre-authorization requests can reduce errors and delays.
Digitalization
Artificial Intelligence (AI) for patient access workflow.
Streamlines the patient access workflow, which in turn helps in getting earlier approval for pre-authorizations.
Machine Learning (ML) for procedures/services prediction.
Helps in predicting procedures and services required by patients and thus enables doctors to commence the process of pre-authorization in advance. It learns from EHR patient data and develops predictions by identifying hidden patterns.
Robotic Process Automation (RPA) for manual business processes
Provides a free platform that utilizes bots in automating manual business processes that take more hours and effort but do not require higher-level thinking.
The Market for Pre-Authorization Automation Solutions
The pre-authorization request, response, and approvals processes are typically manual and time-consuming for physicians. This places a burden on insurance players to be compliant with high-value, quality care in less time.
Tech giants and health IT vendors of all sizes foresee the value and revenue earning opportunities inherent to using technological solutions to create a more efficient workflow. Giving insurance players and providers a streamlined, efficient, and less time-consuming process will benefit all.
Here are a few examples of what’s already happening in the space:
Deloitte, in collaboration with NCT ventures, provides a cloud-based platform that helps in integrating and centralizing the process in hospitals, with health insurers able to check members’ eligibility and whether certain drugs are covered.
Epic Systems, along with startup Klara, will provide the clinical messaging platform that improves communication between patients, their physicians, and insurers.
ZappRx, a mid-sized US-based company, provides a comprehensive digital solution for physicians for specialty prescribing, referrals, and pre-authorization requests. The ZappRx platform can improve the physician prescription approval rate from weeks to just a few days, even for most complex cases.
CenterX offers pre-authorization solutions along with its product offering of medication adherence components. The solution helps doctors be aware of out-of-pocket costs so that patients have the correct information in advance for their prescription therapy plan.
Infinx provides a platform to receive faster Pre-Auth approvals using AI-driven technology plus certified specialists.
Tech giant Apple proposed an iWallet that seamlessly connects providers and payers to assist in seamless referrals and pre-authorizations.
Conclusions
Streamlined, efficient, and real-time interactions will reduce the time spent on pre-authorization tasks for both payers and providers. Reducing delays and increasing staff productivity can then lead to timelier delivery of patient care.
A customer-centric process with refined and precise automated processes can only be achieved with new digital technologies that are regulated in keeping with the latest protocols and criteria.
More and more enterprise organizations are transforming their business and its systems to a more digital-centric paradigm. In their rush to adapt to the fast-paced environment of agile project delivery, continuous development, and automation, companies need a way to conduct tests on products in the development phase.
What is the best practice for accelerating delivery speeds and supporting business goals in next-generation architecture? Learn how zero-touch test automation provides solutions by eliminating manual aspects of the testing process and saving time. Explore the ecosystem of zero-touch testing, the automated CI/CD pipeline, and the benefits of deploying zero-touch automation in your software development environment.
Technological advancements are moving at a rapid pace, especially in architecture where practices are constantly evolving. Modern digital transformation requires the latest architectural practices to cater to the growing demands of businesses and for the scaling of software. In this article, we discuss the most important next-gen architectural practices and their benefits:
Token-Based Authentication
Enhanced DevOps Pipeline
Containerization based code build model
Service-Based Architecture
Limit Stored Procedures
Architecture Best Practices
1. Token-Based Authentication
There are multiple types of authentication techniques, the most common of which is cookie-based. A cookie-based authentication server keeps a record of all database connections on the client side of the cookie, which is stored as a session identifier in the browser.
However, cookie-based authentication has limitations:
Cookie-based authentication is stateful and impacts scalability.
Cookies work on a single domain only.
Tight coupling between client and server.
We recommend the Token-based authentication technique for the next-gen architecture because it is stateless. There are multiple token-based authentication techniques, including the best known and most used JWT (Json web token). The server does not keep a record of users who are logged in or of which JWTs have been issued. Instead, every request on the server is accompanied by a token which the server uses to verify the authenticity of the request.
The token is generally sent as an additional Authorization header in the form of Bearer {JWT}. It can also be sent in either the body or as a query parameter of a POST request. The benefits of using token-based authentication include:
Stateless authentication mechanism.
Improved scalability and performance.
2. Enhanced DevOps Pipeline
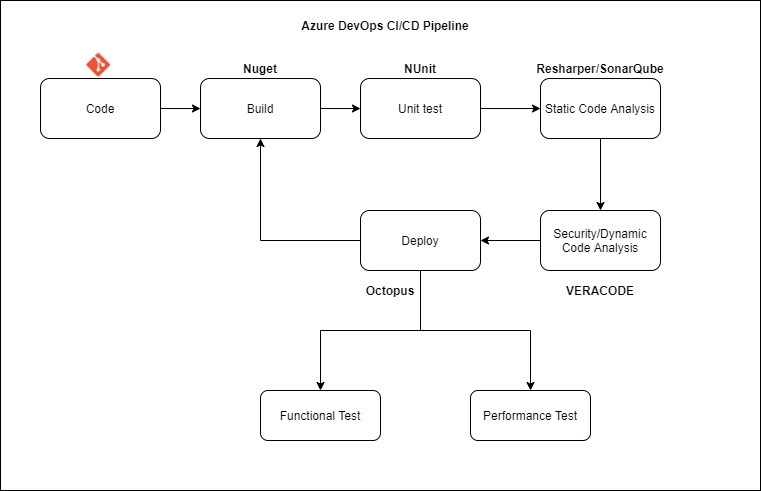
Next, we have an automated CI/CD (Continuous Integration/Continuous Deployment) pipeline for the codebase. This pipeline should deploy the code to different environments; for example, Dev, QA, Product, etc.
Below is a sample of a CI/CD pipeline for .NET projects. As seen in the pipeline, the code repositories are an AzureDevOps code, which is built through the .NET Nuget package manager tool and tested using NUnit.
The Static code analysis of the code is completed initially using a SonarQube or Resharper tool. It then uses dynamic and security testing performed by the Veracode. This is then deployed using the Octopus tool, which can be further tested via a Functional or a Performance test.
Here are the benefits of using an automated CI/CD pipeline:
Auto code deployment to various environments, e.g. QA, Pre-Prod, Product.
Frequent releases.
Integrated Unit testing in CI/CD Pipeline.
Integrated Static Code analysis.
Integrated Security scan.
Improves code quality and consistent code maintenance process.
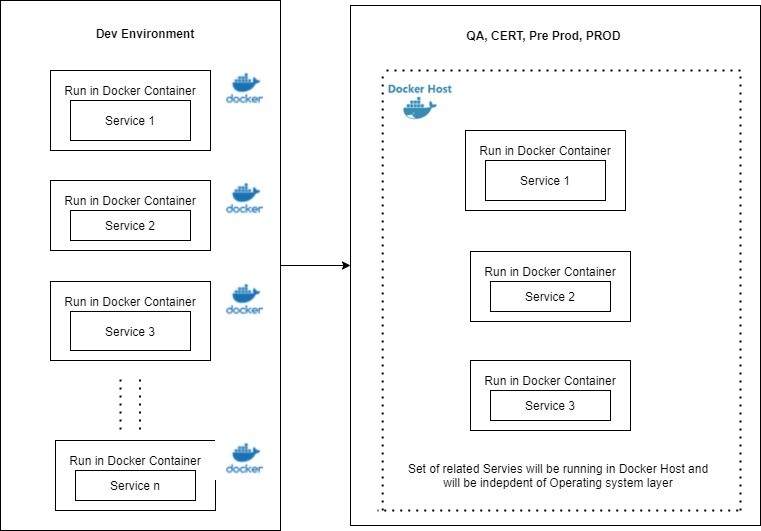
3. Containerization-based code to This runtime Docker application build model
Code building and deployment should be done using a containerization-based approach. Docker is the leading containerization technology. The basic container wraps the application and its dependencies to create a runtime environment for the application.
This runtime Docker application contains work that is seamlessly applied to any environment Dev, QA, Prod, etc. Below is a reference to an architecture diagram for the running code of Docker containers.
Benefits:
All Application codes (API/Service) and their dependencies are packaged as a Docker image and run as a Docker container.
Push Docker images to different environments (QA, CERT, Pre prod, Prod), maintain different Docker versions for images.
Less time and less operational cost in setting up a new environment.
This container-based service can be further scaled to be used independently through a container orchestrator service like Kubernetes.
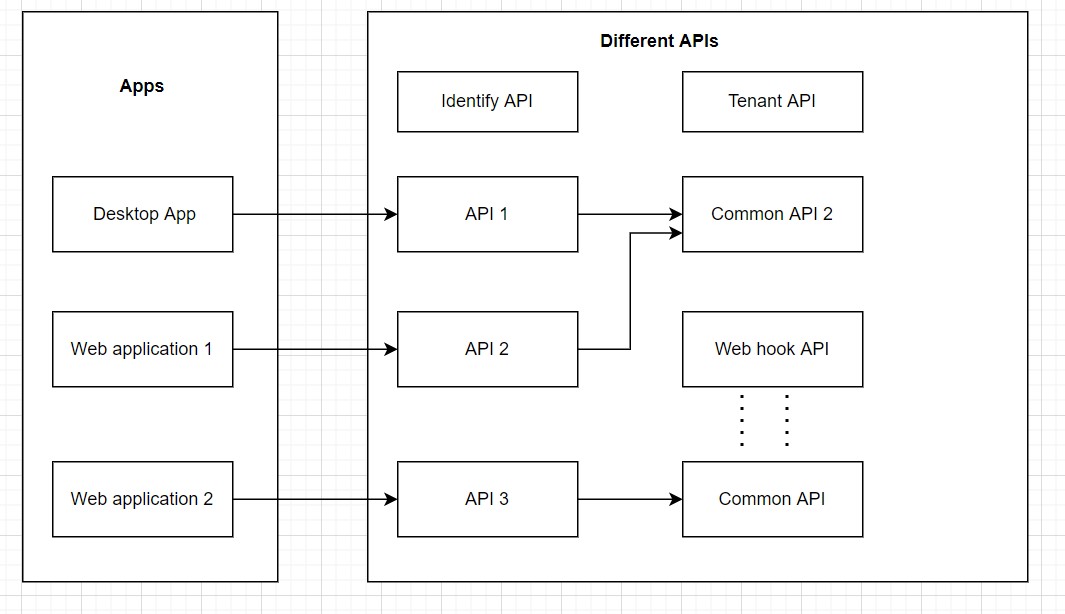
4. Service-Based Architecture
Following a service-based architecture around different business domains enables everything to be serviced as a Rest API or GraphQL, which is easily consumed and reused by other applications. Entire businesses can be approached as a set of independent and accessible APIs.
The following is a reference service-based architecture diagram. The entire business can be seen as a set of Rest API services, which can be easily consumed by business functionalities. This will help to avoid version conflict, remove application compatibility issues, and bring uniformity to the business functionality.
5. Limit Stored Procedures
During the application, stored procedures should be limited as much as possible to avoid:
SPROCs on a database, which will create a monolithic system that cannot be easily scaled.
Limitations in automated testing, debugging, error handling, and maintainability.
Apply these steps to reduce stored procedures while moving to the business (API) layer:
Move the logic of the stored procedure to the business layer of the Rest API/GraphQL handlers. ORM tools like NHibernate/Entity framework can also be used.
Call relevant SQL scripts through DAPR (Micro ORM) in Rest API.
The benefits of using this approach include easier code maintenance and debugging, error handling, and writing automated unit testing as well as improvements in scalability.
Conclusion
The next-gen architecture practices above can be adapted to any project at any scale, offering several benefits to the project’s maintenance. Adopting these architecture best practices will lead to loosely coupled, stateless applications that are easier to build, maintain, test, and deploy.
“True happiness comes only by making others happy.” - David O. McKay
Background and Context
As in the quote above, a data platform can only be truly “happy” if it can make others happy. The others in this context are the actors/teams with whom the data platform interacts, including:
Data Engineers
Data Consumers
Data Analysts
Data Scientists/Machine Learning Engineers
External Data Consumers like partners & data buyers
DataOps Engineers
Data Stewards & Admins (for Data Governance)
While Part I of this blog series covered the perspectives of Data Engineers and Data Consumers, in this second and final post you’ll find the perspectives of DataOps Engineers and Data Stewards & Admins.
Great (User) Expectations
Data Governance
End-to-end data governance encompasses aspects of Data Quality, Data Security and Data Compliance.
It also includes data cataloging, enabling us to discover the data and data lineage. This furthers our understanding of its origins, process, and journey to its current state.
Data stewards want to make sure that all the above aspects are taken care of by the data platform; that all of the data quality, security, and compliance requirements are converted into policies, controls and processes.
Overarching management processes, policies, and control are needed around aspects including the following:
Defining the tags and tagging the data.
Establishing communication and collaboration around the data and the data platform assets.
Monitoring and managing the usage of these assets.
Monitoring and managing the effectiveness and efficiency of these assets.
Defining, monitoring, and managing policies and controls.
Establishing a continuous improvement process of managing feedback/changes such as regulatory ones.
Analysis and improvements across all the three dimensions of quality, security, and compliance.
Implementing workflows to allow search and request for access to existing data assets, as well as requesting the availability of new data.
Enabling enterprise data governance has to be a step-by-step process, and it needs to start with defining MVP based on the specific needs and context. You can keep adding features based on specific priorities, rather than trying to do a “big bang” implementation covering everything all at once.
Data Ops
While DataOps might sound similar to DevOps for data projects, it is much more than that.
DevOps typically covers aspects such as software and services setup, environment provisioning, infrastructure as code, and continuous development, continuous testing, continuous integration, continuous deployment, continuous monitoring, etc.
While DevOps is involved as part of the DataOps, it is only a subset of the whole gamut of aspects that the SuperSet DataOps includes. The high-level objective of DataOps is to make sure that the appropriate data is available to the right consumers, at the right time.
DataOps covers an end-to-end, 360-degree aspect of orchestrating data and converting it into value. It is about enabling an ecosystem of technology, tools, processes, policies, and people to effectively and efficiently ingest, process, store, discover, and consume the data in a secured and compliant manner.
DataOps also involves enabling end users’ trust in the data assets made available to them (which encompasses the aspects covered in Part I of this series).
Accelerate Your Own Data Journey
The objective of a data platform is to eventually enable purposeful, actionable insights that can lead to business outcomes. Additionally, if the data platform puts the right emphasis on the journey and process (i.e., how it can make the job easier for its key actors while delivering the prioritized projects), then it will deliver an ecosystem that is fit for purpose, minimizes waste, and enables a “reuse” mindset.
At GlobalLogic, we are continuously improving our Data Platform Accelerator based on a similar approach. This digital accelerator enables enterprises to immediately manifest a solution that can gather, transform, and enrich data from across their organization. We are excited to work with our clients to accelerate their data journeys and would be happy to discuss your needs with you. Please get in touch using the contact form below.